Navegação IPEN por assunto "machine learning"
- Página inicial
- →
- IPEN
- →
- Navegação IPEN por assunto
- Sobre
- Perfil Técnico
- Política de funcionamento
- Ajuda
- Apresentação
Navegação IPEN por assunto "machine learning"
Itens para a visualização no momento 1-9 de 9
-
MOREIRA, GREGORI de A.
 ; CACHEFFO, ALEXANDRE
; ANDRADE, IZABEL da S.
; LOPES, FABIO JULIANO da S.
; GOMES, ANTONIO A.
; LANDULFO, EDUARDO
. Analyzing the influence of vehicular traffic on the concentration of pollutants in the city of São Paulo: an approach based on pandemic SARS-CoV-2 data and deep learning.
Atmosphere,
v. 14,
n. 10,
p. 1-16,
2023.
DOI:
10.3390/atmos14101578
Abstract:
This study employs surface and remote sensing data jointly with deep learning techniques
to examine the influence of vehicular traffic in the seasonal patterns of CO, NO2
, PM2.5, and PM10
concentrations in the São Paulo municipality, as the period of physical distancing (March 2020 to
December 2021), due to SARS-CoV-2 pandemic and the resumption of activities, made it possible to
observe significant variations in the flow of vehicles in the city of São Paulo. Firstly, an analysis of the
planetary boundary layer height and ventilation coefficient was performed to identify the seasons’
patterns of pollution dispersion. Then, the variations (from 2018 to 2021) of the seasonal average
values of air temperature, relative humidity, precipitation, and thermal inversion occurrence/position
were compared to identify possible variations in the patterns of such variables that would justify (or
deny) the occurrence of more favorable conditions for pollutants dispersion. However, no significant
variations were found. Finally, the seasonal average concentrations of the previously mentioned
pollutants were compared from 2018 to 2021, and the daily concentrations observed during the
pandemic period were compared with a model based on an artificial neural network. Regarding the
concentration of pollutants, the primarily sourced from vehicular traffic (CO and NO2
) exhibited
substantial variations, demonstrating an inverse relationship with the rate of social distancing.
In addition, the measured concentrations deviated from the predictive model during periods of
significant social isolation. Conversely, pollutants that were not primarily linked to vehicular sources
(PM2.5 and PM10) exhibited minimal variation from 2018 to 2021; thus, their measured concentration
remained consistent with the prediction model.
; CACHEFFO, ALEXANDRE
; ANDRADE, IZABEL da S.
; LOPES, FABIO JULIANO da S.
; GOMES, ANTONIO A.
; LANDULFO, EDUARDO
. Analyzing the influence of vehicular traffic on the concentration of pollutants in the city of São Paulo: an approach based on pandemic SARS-CoV-2 data and deep learning.
Atmosphere,
v. 14,
n. 10,
p. 1-16,
2023.
DOI:
10.3390/atmos14101578
Abstract:
This study employs surface and remote sensing data jointly with deep learning techniques
to examine the influence of vehicular traffic in the seasonal patterns of CO, NO2
, PM2.5, and PM10
concentrations in the São Paulo municipality, as the period of physical distancing (March 2020 to
December 2021), due to SARS-CoV-2 pandemic and the resumption of activities, made it possible to
observe significant variations in the flow of vehicles in the city of São Paulo. Firstly, an analysis of the
planetary boundary layer height and ventilation coefficient was performed to identify the seasons’
patterns of pollution dispersion. Then, the variations (from 2018 to 2021) of the seasonal average
values of air temperature, relative humidity, precipitation, and thermal inversion occurrence/position
were compared to identify possible variations in the patterns of such variables that would justify (or
deny) the occurrence of more favorable conditions for pollutants dispersion. However, no significant
variations were found. Finally, the seasonal average concentrations of the previously mentioned
pollutants were compared from 2018 to 2021, and the daily concentrations observed during the
pandemic period were compared with a model based on an artificial neural network. Regarding the
concentration of pollutants, the primarily sourced from vehicular traffic (CO and NO2
) exhibited
substantial variations, demonstrating an inverse relationship with the rate of social distancing.
In addition, the measured concentrations deviated from the predictive model during periods of
significant social isolation. Conversely, pollutants that were not primarily linked to vehicular sources
(PM2.5 and PM10) exhibited minimal variation from 2018 to 2021; thus, their measured concentration
remained consistent with the prediction model.
Palavras-Chave: urban areas; air pollution; air quality; machine learning; vehicles; coronaviruses
. Analyzing the influence of vehicular traffic on the concentration of pollutants in the city of São Paulo: an approach based on pandemic SARS-CoV-2 data and deep learning. Atmosphere, v. 14, n. 10, p. 1-16, 2023. DOI: 10.3390/atmos14101578. Disponível em: http://repositorio.ipen.br/handle/123456789/34210. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.

-
PERIGO, ELIO A.; FARIA, RUBENS N. de
. Artificial intelligence-engineering magnetic materials: current status and a brief perspective.
Magnetochemistry,
v. 7,
n. 6,
p. 1-11,
2021.
DOI:
10.3390/magnetochemistry7060084
Abstract:
The implementation of artificial intelligence into the research and development of (currently)
the most economically relevant classes of engineering hard and soft magnetic materials
is addressed. Machine learning is nowadays the key approach utilized in the discovery of new
compounds, physical–chemical properties prediction, microstructural/magnetic characterization,
and applicability of permanent magnets and crystalline/amorphous soft magnetic alloys. Future
opportunities are envisioned on at least two fronts: (a) ultra-low losses materials, as well as processes
that enable their manufacturing, unlocking the next step for higher efficiency electrification,
power conversion, and distribution; (b) additively manufactured magnetic materials by predicting
and developing novel powdered materials properties, generative design concepts, and optimal
processing conditions.
Palavras-Chave: magnetic materials; programming; artificial intelligence; artificial intelligence; amorphous state; machine learning
. Artificial intelligence-engineering magnetic materials: current status and a brief perspective. Magnetochemistry, v. 7, n. 6, p. 1-11, 2021. DOI: 10.3390/magnetochemistry7060084. Disponível em: http://repositorio.ipen.br/handle/123456789/32308. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
ANDRADE, DELVONEI A. de
; MESQUITA, ROBERTO N. de
; NASCIMENTO, NATAN P.. A comparative study on machine learning regression algorithms aplied to modeling gas centrifuge / Um estudo comparativo sobre algoritmos de regressão de aprendizagem de máquinas aplicado à modelagem de centrífugas a gás.
Brazilian Journal of Development,
v. 8,
n. 7,
p. 52669-52681,
2022.
DOI:
10.34117/bjdv8n7-265
Abstract:
The gas Centrifuge is a very hard equipment to model, because it involves a gas dynamic with many complications, such as hypersonic waves and rarefied regions combined with continuous flow areas. Therefore, data analysis regressions remain currently a very important technique to understand and describe the problem in a practical way. This paper intends to apply and compare several regression techniques using machine learning, to obtain a hydraulic and a separative power model of gas centrifuge used in enrichment plants. For this purpose, a set of normalized data composed of 134 experimental lines was used, observing the variables of interest, the separation power (dU), and the waste pressure (Pw), through the following explanatory variables: feed flow (F), cut (q), and product pressure (Pp). The comparisons were presented between the results obtained for the models generated by the following: algorithms, multivariate regression, multivariate adaptive regression splines – MARS, bootstrap aggregating multivariate adaptive regression splines – Bagging MARS, artificial neural network – ANN, extreme gradient boosting – XGBoost, support vector regression– Poly SVR, radial basis Function support vector regression – RBF SVR, K-nearest neighbors – KNN and Stacked Ensemble. That way, to avoid overfitting and provide insights about generalization of the models in unseen data, during the training phase, the k-fold cross validation approach was used. Subsequently, the residuals were analyzed, and the models were compared by the following metrics: Root mean square error – RMSE; Mean squared error – MSE; Mean absolute error – MAE; and Coefficient of determination – R2.
Palavras-Chave: isotope separation; gas centrifuges; machine learning; multivariate analysis; neural networks; algorithms; automation
. A comparative study on machine learning regression algorithms aplied to modeling gas centrifuge. Brazilian Journal of Development, v. 8, n. 7, p. 52669-52681, 2022. DOI: 10.34117/bjdv8n7-265. Disponível em: http://repositorio.ipen.br/handle/123456789/33380. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
VALLE, MATHEUS del
; SANTOS, MOISES O. dos
; SANTOS, SOFIA N. dos
; BERNARDES, EMERSON S.
; ZEZELL, DENISE M.
. Evaluation of machine learning models for the classification of breast cancer hormone receptors using micro-FTIR images.
In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE,
May 31 - June 2, 2021,
Online.
Proceedings...
Piscataway, NJ, USA: IEEE,
2021.
DOI:
10.1109/SBFOTONIOPC50774.2021.9461946
Abstract:
The breast cancer is the most incident cancer in
women. Evaluation of hormone receptors expression plays an
important role to outline treatment strategies. FTIR
spectroscopy imaging may be employed as an additional
technique, providing extra information to help physicians. In
this work, estrogen and progesterone receptors expression were
evaluated using tumors biopsies from human cell lines
inoculated in mice. FTIR images were collect from histological
sections, and six machine learning models were applied and
assessed. Xtreme gradient boost and Linear Discriminant
Analysis presented the best accuracies results, indicating to be
potential models for breast cancer classification tasks.
Palavras-Chave: mammary glands; neoplasms; fourier transformation; images; machine learning; hormones; receptors
. Evaluation of machine learning models for the classification of breast cancer hormone receptors using micro-FTIR images. In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE, May 31 - June 2, 2021, Online. Proceedings... Piscataway, NJ, USA: IEEE, 2021. DOI: 10.1109/SBFOTONIOPC50774.2021.9461946. Disponível em: http://repositorio.ipen.br/handle/123456789/32334. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
DEL VALLE, MATHEUS
; STANCARI, KLEBER
; CASTRO, PEDRO A.A. de
; SANTOS, MOISES O. dos
; ZEZELL, DENISE M.
. Machine Learning methods for micro-FTIR imaging classification of human skin tumors.
In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE,
May 31 - June 2, 2021,
Online.
Proceedings...
Piscataway, NJ, USA: IEEE,
2021.
DOI:
10.1109/SBFotonIOPC50774.2021.9461969
Abstract:
This review presents some methods applied to
micro-FTIR imaging for classification of human skin tumors.
It is a collection of the pre-processing pipeline and machine
learning classification models. The aim of this review is to
update and summaiize the current methods which an applied
in our skin tumor research.
Palavras-Chave: skin diseases; tumor cells; infrared radiation; fourier transformation; machine learning; spectra
. Machine Learning methods for micro-FTIR imaging classification of human skin tumors. In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE, May 31 - June 2, 2021, Online. Proceedings... Piscataway, NJ, USA: IEEE, 2021. DOI: 10.1109/SBFotonIOPC50774.2021.9461969. Disponível em: http://repositorio.ipen.br/handle/123456789/32339. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
VANHOZ, RAFAEL
; MORALLES, MAURICIO
; DIAS, MAURO da S.
. Machine learning techniques for simultaneous determination of parameters associated with the k0 method of neutron activation analysis.
In: INTERNATIONAL NUCLEAR ATLANTIC CONFERENCE,
November 29 - December 2, 2021,
Online.
Proceedings...
Rio de Janeiro: Associação Brasileira de Energia Nuclear,
2021.
Palavras-Chave: irradiation; elements; machine learning; algorithms; programming languages; statistical data
. Machine learning techniques for simultaneous determination of parameters associated with the k0 method of neutron activation analysis. In: INTERNATIONAL NUCLEAR ATLANTIC CONFERENCE, November 29 - December 2, 2021, Online. Proceedings... Rio de Janeiro: Associação Brasileira de Energia Nuclear, 2021. Disponível em: http://repositorio.ipen.br/handle/123456789/32498. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
FAROOQ, SAJID
; DEL-VALLE, MATHEUS
; SANTOS, MOISES O. dos; SANTOS, SOFIA N. dos
; BERNARDES, EMERSON S.
. Rapid identification of breast cancer subtypes using micro-FTIR and machine learning methods.
Applied Optics,
v. 62,
n. 8,
p. C80 - C87,
2023.
DOI:
10.1364/AO.477409
Abstract:
Breast cancer (BC) molecular subtypes diagnosis involves improving clinical uptake by Fourier transform infrared
(FTIR) spectroscopic imaging, which is a non-destructive and powerful technique, enabling label free extraction of biochemical information towards prognostic stratification and evaluation of cell functionality. However,
methods of measurements of samples demand a long time to achieve high quality images, making its clinical use
impractical because of the data acquisition speed, poor signal to noise ratio, and deficiency of optimized computational framework procedures. To address those challenges, machine learning (ML) tools can facilitate obtaining
an accurate classification of BC subtypes with high actionability and accuracy. Here, we propose a ML-algorithmbased method to distinguish computationally BC cell lines. The method is developed by coupling the K-neighbors
classifier (KNN) with neighborhood components analysis (NCA), and hence, the NCA-KNN method enables
to identify BC subtypes without increasing model size as well as adding additional computational parameters.
By incorporating FTIR imaging data, we show that classification accuracy, specificity, and sensitivity improve,
respectively, 97.5%, 96.3%, and 98.2%, even at very low co-added scans and short acquisition times. Moreover, a
clear distinctive accuracy (up to 9 %) difference of our proposed method (NCA-KNN) was obtained in comparison
with the second best supervised support vector machine model. Our results suggest a key diagnostic NCA-KNN
method for BC subtypes classification that may translate to advancement of its consolidation in subtype-associated
therapeutics.
Palavras-Chave: diagnosis; diagnostic techniques; neoplasms; mammary glands; fourier transformation; infrared spectrometers; machine learning
. Rapid identification of breast cancer subtypes using micro-FTIR and machine learning methods. Applied Optics, v. 62, n. 8, p. C80 - C87, 2023. DOI: 10.1364/AO.477409. Disponível em: http://repositorio.ipen.br/handle/123456789/34165. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
FAROOQ, SAJID
; CARAMEL-JUVINO, AMANDA
; DEL-VALLE, MATHEUS
; SANTOS, SOFIA
; BERNARDES, EMERSON S.
; ZEZELL, DENISE M.
. Superior Machine Learning Method for breast cancer cell lines identification.
In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE,
October 13-15, 2022,
Recife, PE.
Proceedings...
Piscataway, NJ, USA: IEEE,
2022.
DOI:
10.1109/SBFotonIOPC54450.2022.9992467
Abstract:
We propose an artificial intelligence platform based on machine learning (ML) algorithm using Neighborhood Component analysis and K-Nearest Neighbors for breast cancer cell lines recognition. Our model presents up to 97% accuracy for identification of breast cancer cell lines.
Palavras-Chave: neoplasms; mammary glands; tumor cells; machine learning; artificial intelligence; accuracy; identification systems
. Superior Machine Learning Method for breast cancer cell lines identification. In: SBFOTON INTERNATIONAL OPTICS AND PHOTONICS CONFERENCE, October 13-15, 2022, Recife, PE. Proceedings... Piscataway, NJ, USA: IEEE, 2022. DOI: 10.1109/SBFotonIOPC54450.2022.9992467. Disponível em: http://repositorio.ipen.br/handle/123456789/33669. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
-
DEL-VALLE, MATHEUS
; SANTOS, MOISES O. dos
; SANTOS, SOFIA N. dos
; CASTRO, PEDRO A.A. de
; BERNARDES, EMERSON S.
; ZEZELL, DENISE M.
. The impact of scan number and its preprocessing in micro-FTIR imaging when applying machine learning for breast cancer subtypes classification.
Vibrational Spectroscopy,
v. 117,
p. 1-6,
2021.
DOI:
10.1016/j.vibspec.2021.103309
Abstract:
The breast cancer molecular subtype is an important classification to outline the prognostic. Gold-standard assessing using immunohistochemistry adds subjectivity due to interlaboratory and interobserver variations. In order to increase the diagnosis confidence, other techniques need to be examined, where the FTIR spectroscopy imaging allied with machine learning techniques may provide additional and quantitative information regarding the molecular composition. However, the impact of co-added scans acquisition parameter into machine learning classifications still needs better evaluation. In this study, FTIR images of Luminal B and HER2 subtypes were acquired varying the scan number and preprocessing techniques. It was demonstrated a spectral quality improvement when the scan number was increased, decreasing the standard deviation and outliers. Six machine learning models were used to classify the subtypes: Linear Discriminant Analysis, Partial Least Squares Discriminant Analysis, K-Nearest Neighbors, Support Vector Machine, Random Forest and Extreme Gradient Boosting. Best mean accuracy of 0.995 was achieved by Extreme Gradient Boosting model. It was found that all models achieved similar high accuracies with groups b256_064 (256 background and 064 scans), b256_128 and b128_128. Besides assessing the performance of different models, the b256_064 was established as the optimal group due to the minimum acquisition time. Therefore, this work indicates b256_064 for breast cancer subtype classification and also as a basis for other studies using machine learning for cancer evaluation.
Palavras-Chave: fourier transform spectrometers; mammary glands; neoplasms; machine learning; histological techniques
. The impact of scan number and its preprocessing in micro-FTIR imaging when applying machine learning for breast cancer subtypes classification. Vibrational Spectroscopy, v. 117, p. 1-6, 2021. DOI: 10.1016/j.vibspec.2021.103309. Disponível em: http://repositorio.ipen.br/handle/123456789/32398. Acesso em: $DATA.Como referenciar este itemEsta referência é gerada automaticamente de acordo com as normas do estilo IPEN/SP (ABNT NBR 6023) e recomenda-se uma verificação final e ajustes caso necessário.
Itens para a visualização no momento 1-9 de 9
Buscar no repositório
Navegar
Minha conta
Visualizar
A pesquisa no RD utiliza os recursos de busca da maioria das bases de dados. No entanto algumas dicas podem auxiliar para obter um resultado mais pertinente.
✔ É possível efetuar a busca de um autor ou um termo em todo o RD, por meio do Buscar no Repositório , isto é, o termo solicitado será localizado em qualquer campo do RD. No entanto esse tipo de pesquisa não é recomendada a não ser que se deseje um resultado amplo e generalizado.
✔ A pesquisa apresentará melhor resultado selecionando um dos filtros disponíveis em Navegar
✔ Os filtros disponíveis em Navegar tais como: Coleções, Ano de publicação, Títulos, Assuntos, Autores, Revista, Tipo de publicação são autoexplicativos. O filtro, Autores IPEN apresenta uma relação com os autores vinculados ao IPEN; o ID Autor IPEN diz respeito ao número único de identificação de cada autor constante no RD e sob o qual estão agrupados todos os seus trabalhos independente das variáveis do seu nome; Tipo de acesso diz respeito à acessibilidade do documento, isto é , sujeito as leis de direitos autorais, ID RT apresenta a relação dos relatórios técnicos, restritos para consulta das comunidades indicadas.

A opção Busca avançada utiliza os conectores da lógica boleana, é o melhor recurso para combinar chaves de busca e obter documentos relevantes à sua pesquisa, utilize os filtros apresentados na caixa de seleção para refinar o resultado de busca. Pode-se adicionar vários filtros a uma mesma busca.
Exemplo:
Buscar os artigos apresentados em um evento internacional de 2015, sobre loss of coolant, do autor Maprelian.
Autor: Maprelian
Título: loss of coolant
Tipo de publicação: Texto completo de evento
Ano de publicação: 2015
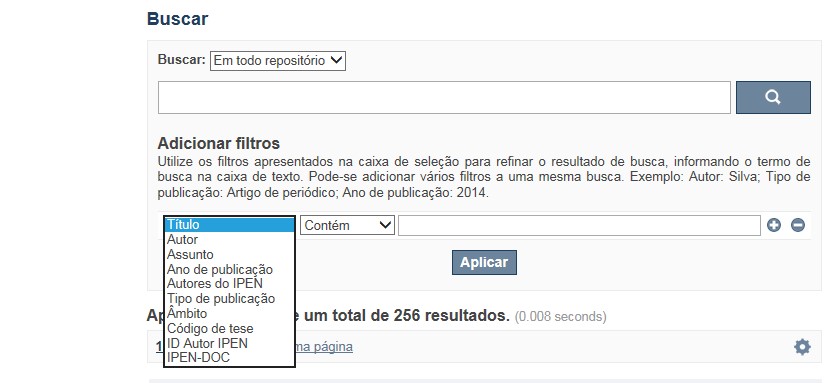
✔ Para indexação dos documentos é utilizado o Thesaurus do INIS, especializado na área nuclear e utilizado em todos os países membros da International Atomic Energy Agency – IAEA , por esse motivo, utilize os termos de busca de assunto em inglês; isto não exclui a busca livre por palavras, apenas o resultado pode não ser tão relevante ou pertinente.
✔ 95% do RD apresenta o texto completo do documento com livre acesso, para aqueles que apresentam o ![]() significa que e o documento está sujeito as leis de direitos autorais, solicita-se nesses casos contatar a Biblioteca do IPEN,
bibl@ipen.br
.
significa que e o documento está sujeito as leis de direitos autorais, solicita-se nesses casos contatar a Biblioteca do IPEN,
bibl@ipen.br
.
✔ Ao efetuar a busca por um autor o RD apresentará uma relação de todos os trabalhos depositados no RD. No lado direito da tela são apresentados os coautores com o número de trabalhos produzidos em conjunto bem como os assuntos abordados e os respectivos anos de publicação agrupados.
✔ O RD disponibiliza um quadro estatístico de produtividade, onde é possível visualizar o número dos trabalhos agrupados por tipo de coleção, a medida que estão sendo depositados no RD.
✔ Na página inicial nas referências são sinalizados todos os autores IPEN, ao clicar nesse símbolo ![]() será aberta uma nova página correspondente à aquele autor – trata-se da página do pesquisador.
será aberta uma nova página correspondente à aquele autor – trata-se da página do pesquisador.
✔ Na página do pesquisador, é possível verificar, as variações do nome, a relação de todos os trabalhos com texto completo bem como um quadro resumo numérico; há links para o Currículo Lattes e o Google Acadêmico ( quando esse for informado).
ATENÇÃO!
ESTE TEXTO "AJUDA" ESTÁ SUJEITO A ATUALIZAÇÕES CONSTANTES, A MEDIDA QUE NOVAS FUNCIONALIDADES E RECURSOS DE BUSCA FOREM SENDO DESENVOLVIDOS PELAS EQUIPES DA BIBLIOTECA E DA INFORMÁTICA.
O gerenciamento do Repositório está a cargo da Biblioteca do IPEN. Constam neste RI, até o presente momento 20.950 itens que tanto podem ser artigos de periódicos ou de eventos nacionais e internacionais, dissertações e teses, livros, capítulo de livros e relatórios técnicos. Para participar do RI-IPEN é necessário que pelo menos um dos autores tenha vínculo acadêmico ou funcional com o Instituto. Nesta primeira etapa de funcionamento do RI, a coleta das publicações é realizada periodicamente pela equipe da Biblioteca do IPEN, extraindo os dados das bases internacionais tais como a Web of Science, Scopus, INIS, SciElo além de verificar o Currículo Lattes. O RI-IPEN apresenta também um aspecto inovador no seu funcionamento. Por meio de metadados específicos ele está vinculado ao sistema de gerenciamento das atividades do Plano Diretor anual do IPEN (SIGEPI). Com o objetivo de fornecer dados numéricos para a elaboração dos indicadores da Produção Cientifica Institucional, disponibiliza uma tabela estatística registrando em tempo real a inserção de novos itens. Foi criado um metadado que contém um número único para cada integrante da comunidade científica do IPEN. Esse metadado se transformou em um filtro que ao ser acionado apresenta todos os trabalhos de um determinado autor independente das variáveis na forma de citação do seu nome.
A elaboração do projeto do RI do IPEN foi iniciado em novembro de 2013, colocado em operação interna em julho de 2014 e disponibilizado na Internet em junho de 2015. Utiliza o software livre Dspace, desenvolvido pelo Massachusetts Institute of Technology (MIT). Para descrição dos metadados adota o padrão Dublin Core. É compatível com o Protocolo de Arquivos Abertos (OAI) permitindo interoperabilidade com repositórios de âmbito nacional e internacional.
1. Portaria IPEN-CNEN/SP nº 387, que estabeleceu os princípios que nortearam a criação do RDI, clique aqui.
2. A experiência do Instituto de Pesquisas Energéticas e Nucleares (IPEN-CNEN/SP) na criação de um Repositório Digital Institucional – RDI, clique aqui.
O Repositório Digital do IPEN é um equipamento institucional de acesso aberto, criado com o objetivo de reunir, preservar, disponibilizar e conferir maior visibilidade à Produção Científica publicada pelo Instituto, desde sua criação em 1956.
Operando, inicialmente como uma base de dados referencial o Repositório foi disponibilizado na atual plataforma, em junho de 2015. No Repositório está disponível o acesso ao conteúdo digital de artigos de periódicos, eventos, nacionais e internacionais, livros, capítulos, dissertações, teses e relatórios técnicos.
A elaboração do projeto do RI do IPEN foi iniciado em novembro de 2013, colocado em operação interna em julho de 2014 e disponibilizado na Internet em junho de 2015. Utiliza o software livre Dspace, desenvolvido pelo Massachusetts Institute of Technology (MIT). Para descrição dos metadados adota o padrão Dublin Core. É compatível com o Protocolo de Arquivos Abertos (OAI) permitindo interoperabilidade com repositórios de âmbito nacional e internacional.
O gerenciamento do Repositório está a cargo da Biblioteca do IPEN. Constam neste RI, até o presente momento 20.950 itens que tanto podem ser artigos de periódicos ou de eventos nacionais e internacionais, dissertações e teses, livros, capítulo de livros e relatórios técnicos. Para participar do RI-IPEN é necessário que pelo menos um dos autores tenha vínculo acadêmico ou funcional com o Instituto. Nesta primeira etapa de funcionamento do RI, a coleta das publicações é realizada periodicamente pela equipe da Biblioteca do IPEN, extraindo os dados das bases internacionais tais como a Web of Science, Scopus, INIS, SciElo além de verificar o Currículo Lattes. O RI-IPEN apresenta também um aspecto inovador no seu funcionamento. Por meio de metadados específicos ele está vinculado ao sistema de gerenciamento das atividades do Plano Diretor anual do IPEN (SIGEPI). Com o objetivo de fornecer dados numéricos para a elaboração dos indicadores da Produção Cientifica Institucional, disponibiliza uma tabela estatística registrando em tempo real a inserção de novos itens. Foi criado um metadado que contém um número único para cada integrante da comunidade científica do IPEN. Esse metadado se transformou em um filtro que ao ser acionado apresenta todos os trabalhos de um determinado autor independente das variáveis na forma de citação do seu nome.